大規模分散データベースGoogle Cloud Spannerに階層型ストレージが導入、コールドデータをSSDからHDDに自動移行
今回は「大規模分散データベースGoogle Cloud Spannerに階層型ストレージが導入、コールドデータをSSDからHDDに自動移行」についてご紹介します。
関連ワード (発表、説明、階層化等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
Google Cloudは、Google Cloud Spannerデータベース(以下、Spanner)に、階層型ストレージの機能を導入したことを発表しました。
Spannerはトランザクション機能を備えたリレーショナルデータベースでありながら、事実上無限のスケーラビリティを備える大規模分散データベースです。グラフデータベース機能やベクトル検索などにも対応しています。
Spannerは大規模なデータを扱えるデータベースであるがゆえに、大量のデータが登録される使い方が行われることになりますが、その中では頻繁にアクセスされる、いわゆるホットなデータと、あまりアクセスされなくなっていく、いわゆるコールドなデータに分かれていきます。
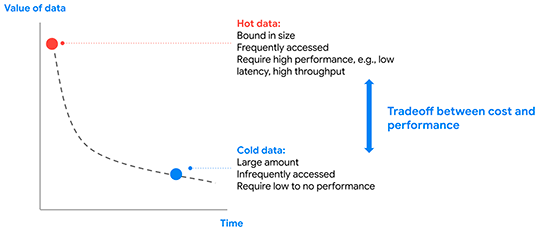
今回の階層ストレージ機能によってコールドデータをSSDからHDDのストレージへ自動的に移動させることができるようになりました。
安価なHDDのストレージにデータを移動することでコールドデータへのアクセスは遅くなるものの、Spannerの運用コストを下げることができること、そしてSpannerデータベース内の中でその移動が自動的に行われることで手間がかからず、しかもユーザーからはいままでと同様の使い方ができるといった利点が得られます。
階層化の指示はポリシーによって設定でき、データベース、テーブル、カラム、またはセカンダリインデックスに適用できます。例えばあまりクエリが実行されない列のデータを移動する、あるいは一部のインデックスをSSDに置いてデータそのものはHDDに置くといったことが可能だと説明されています。
階層化機能はSpannerのEntepriseとEnterprise Plusエディションに対応し、Spannerが利用可能なすべてのリージョンで利用可能です。