複雑なシステムでは、すべての要素が正しくても障害が起きる。カオスエンジニアリングから継続的検証へ(前編)。JaSST'23 Tokyo基調講演
今回は「複雑なシステムでは、すべての要素が正しくても障害が起きる。カオスエンジニアリングから継続的検証へ(前編)。JaSST'23 Tokyo基調講演」についてご紹介します。
関連ワード (冗長化、登壇、結果等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
Netflixが始めた「カオスエンジニアリング」は、現在では大規模なシステムにおける可用性向上の手法のひとつとして確立し、広く知られるようになりました。
そのカオスエンジニアリングという手法を定義したのが、元Netflixカオスエンジニアリングチームのエンジニアリングマネージャーを務めていたCasey Rosenthal(ケイシー ローゼンタール)氏です。
そのローゼンタール氏が、ソフトウェアのテストに関わる国内最大のイベント「ソフトウェアテストシンポジウム 2023 東京」(JaSST’23 Tokyo)の基調講演に登壇し、「Chaos Engineering to Continuous Verification」(カオスエンジニアリングから継続的検証へ)という講演を行いました。
講演では、カオスエンジニアリングの成り立ちと、従来のテスト手法とカオスエンジニアリングの本質的な違い、そしてなぜ大規模システムにおいてカオスエンジニアリングが欠かせないのか、などが解説されました。
この記事では、その基調講演の内容をダイジェストで紹介します。記事は前編、中編、後編(明日、4月25日公開予定)の3つに分かれています。いまお読みの記事は前編です。
Chaos Engineering to Continuous Verification
皆さんこんにちは。今日は「カオスエンジニアリング」(Chaos Engineering)という、ソフトウェアエンジニアリングの分野についてお話をしたいと思います。

カオスエンジニアリングは私がNetflixではじめて定義したもので、これがソフトエンジニアリング業界に大きな影響をもたらしています。
カオスエンジニアリングはContinuous Verification(CV:継続的検証)と関係していますし、QAとも、ソフトウェアテストとも関連しています。
そして、いわゆるハイパースケーラーと呼ばれるAmazon、Google、Facebook、マイクロソフトなどはカオスエンジニアリングを採用していますし、インターネットのデジタルネイティブな企業、ニューヨークにある大手銀行でも採用しています。
今日はこの新しい分野についての由来や、ソフトウェアテスト、ソフトウェアエンジニアリングなどにどういった影響をもたらしたかの話をしたいと思います。
当時のクラウドはインスタンスが突然消えた
Chaos Monkey(カオスモンキー)というプログラムは15年ほど前にNetflixで開発され注目を集めました。
当時Netflixは大規模なサービスとして初めてクラウドに移行した企業の1つで、AWSの最初の大きな顧客の1つでした。
同社はビデオストリーミングの巨大なシステムを、専用のマシンからクラウドの中でスケールする何千というインスタンスへと移行したのです。
しかしその最初の数カ月で悪評が立ちました。というのもサービスのアベイラビリティが低かったのです。
その大きな原因の1つが、当時のクラウドでインスタンスが突然消えるという現象でした。予告なくインスタンスが消えてしまうのです。そうするとNetflixのストリーミングシステム全体がクラッシュする状況でした。
Netflixはこれをいろんな形で解決しようとして、そしてChaos Monkeyの開発に至りました。

(注:Chaos Monkeyは2012年にオープンソースとして公開)
参考:サービス障害を起こさないために、障害を起こし続ける。逆転の発想のツールChaos Monkeyを、Netflixがオープンソースで公開
ChaosMonkeyによって1週間で問題が解消された
Chaos Monkeyは何をするのかというと、1日に1回、業務時間中にサービス中のインスタンスを意図的にシャットダウンさせます。
そのことによって強制的に、全てのエンジニアが通じてインスタンスが予告なく消える状態に対処しなければならなくなったわけです。
すると、Netflixのアベイラビリティの問題は1週間でなくなりました。全てのエンジニアが、この問題を解決しないと他に何も仕事ができない、という状況になったからです。
Chaos Monkeyによって、Netflixが解決しなければならない問題にエンジニアも力を入れざるをえない得なくなったわけです。
これは直感に反するやり方でしたが、しかし非常に効果的でした。
そこでNetflixはこれを大規模に展開しようとしました。つまり意図的にインスタンスをシャットオフするだけではなく、データセンター全体をシャットオフしたらどうか、あるいはリージョン全体をシャットオフしたらどうだろうか、としたわけです。
そのためのシステムを「Chaos Kong」と呼び、それを月に1回、さらには週に1回とやっていきました。

Netflixは3つのリージョンを使っていて、その内の1つを選んでエンジニアに予告なくシャットオフしました。そのリージョンはAWSの他のお客様も利用しているため、リージョン全体を完全にはオフにできませんが、シミュレーションはうまくいきました。
Chaos MonkeyやChaos Kongは、Netflixのビジネスで解決しなければならない課題をエンジニアに対して明確に示したわけです。
そしてエンジニアは、その課題に対するエンジニアリングソリューションを見出すことができました。
AWSは1年に1回程度まだインスタンスやリージョンの問題が発生しますが、それによってNetflixで問題が引き起こされることはなくなったのです。
エンジニア自身が問題解決をする
Chaos MonkeyやChaos Kongがなぜ必要なのでしょうか。
これはNetflixのマイクロサービスのアーキテクチャの図です。8年前のものです。

マイクロサービスは日々変わっています。場合によっては1日に数回変わっています。エンジニアリングチームが変えているわけです。
そのエンジニアリングチームは自分のマイクロサービスはよく知っています。あるいは1つか2つ隣にあるマイクロサービスはわかっています。
けれどもそれ以降のものについては、よく分かっていません。リクエストパスを追跡しなければ無理ですし、それをする十分な時間が人間の人生にはありませんので、全てのマイクロサービスを知ることはできません。
そしてNetflixにはチーフアーキテクトやCTOという立場の人はいません。チームに対して、こうやってやりなさいという人がいなかったわけです。
ですので、エンジニア自身が自分のマイクロサービスの責任を持ち、さらにマイクロサービスのパートナーともコミュニケーションを取らなければなりません。そうしないとシステム全体が立ち上がりません。
ですからNetflixでは1人1人が問題を解決しなければならなかったわけです。自分のやり方で解決することも可能となっていました。
だからこそChaos Monkeyが必要だったわけです。
Chaos Monkeyはリクエスト間にレイテンシ(遅延)を挿入することも可能でした。非常に複雑な分散システムでは、レイテンシが一番よくシステムが破綻する理由だったからです。
Chaos Monkeyのおかげで、Netflixはレイテンシが高くてもサービスが機能するようにできました。
事例1:ステージング環境を止めたら本番環境まで止まった
では複雑なシステムにおいて、どのようなことで障害が起こりうるのでしょうか?
3つの実例を挙げて、複雑なシステムではどういう風に問題が起こりうるか、という話をしようと思います。

1番目の例です。これは非常に大手の小売業で、その後Amazon.comが買収しました。
彼らはGame Dayというイベントを行っていました。
Game Dayは、システムに問題が起きたときそれにどう対処するか、というアイディアを出す日です。全員が会議室に集まって、最近ではバーチャルでもできるんですけれども、全員がシステムを見て、ある問題が起きたらシステムはこう振る舞うだろうと予測し、その通りにシステムが振る舞うかどうかを実際に試していたのです。
この日はまず、クラウド上に本番環境のコピーであるステージング環境が作られました。真ん中にメッセージングバスとしてkafkaクラスタが導入されています。
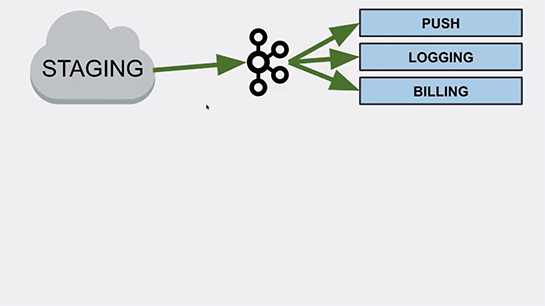
Kafkaクラスタは、スマートフォンへのプッシュ通知送信、アプリケーションのロギング、そして課金のバッチ処理という3つの作業をしています。
ここでステージング環境のKafkaクラスタが止まったとき、Kafkaをご存じの方はこうしたことが起こりうることはご存じだと思いますが、ステージング環境のKafkaクラスタが止まったときに何が起こるか? を予測したのです。
本番環境では、このステージング環境のコピーが稼働していました。
そこで、ステージング環境での通知やロギングや課金の処理は止まるけれども、本番環境は継続して機能するだろうと予測したわけです。
そしてステージング環境のKafkaクラスタを止めて、その予測通りにシステムが振る舞うかを見てみました。
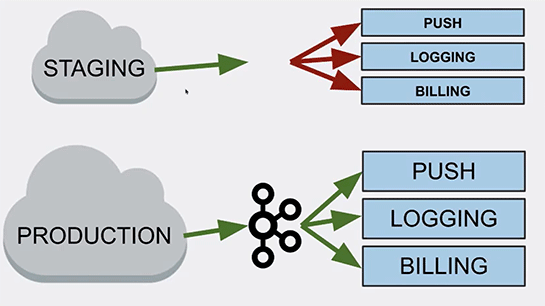
で、実際に止めてみると、実際には本番環境まで全部駄目になってしまったんです。
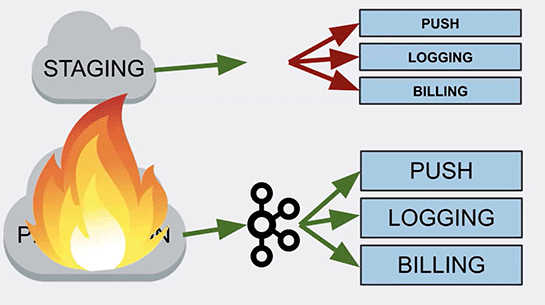
幸いにもGame Dayとしてのイベントだったので、すぐに元に戻すことができたのですが、では実際に何が起きたのかを調べてみると、分かったのは本番環境のロギング処理が、ステージング環境のKafkaクラスタに向けて実行されていた、ということだったのです。
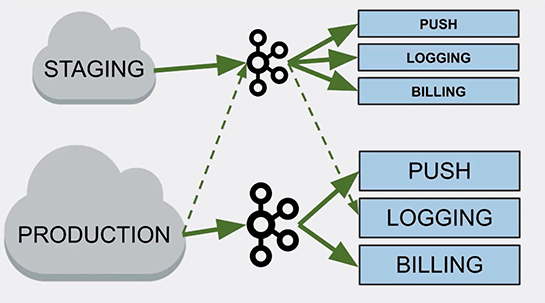
ステージング環境から本番環境へとデプロイしたときに、コンフィグレーションファイルの一部がステージング環境のKafkaクラスタに向けてロギングを行う設定のままであった、ということを見逃していたのです。
そのために、ステージング環境のKafkaクラスタを止めると、本番環境のアプリケーションがログに書き込めなくなり、Javaのスレッドプールが一杯になってしまい、システムダウンになったわけです。
これは確かに発見しにくい設定だと思います。実際に本番環境での処理が問題なく走っていたわけですから。
Game Dayで試したおかげで、このことが分かって幸運だったと思います。もしも通常時にこの障害が起きたら、壊滅的な影響をお客様に及ぼしていたかもしれません。
事例2:矛盾した処理の発生でシステムが止まる
続いて2番目の例です。
これは大手のオンラインサービス会社の例です。個人データを入出力します。
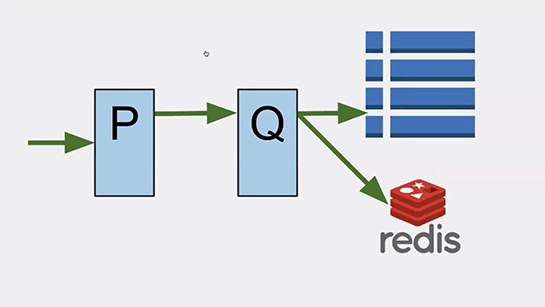
「P」はデータのフォーマッティング処理などを行うサービスで、ここで受け取るデータは削除されず、つねに追加か更新のみが行われる仕組みを備えていました。
「Q」はデータの保存や参照の処理を行うサービスです。データベースにはCassandraを使っていてここにデータが保存されます。さらにインメモリキャッシュとしてRedisを使って高速化を図っています。
「Q」はデフォルトではRedisにデータを参照しに行くことで、高速な処理を行っており、万が一Redisが駄目になったときにはCassandraへ参照しに行くようになっていました。
さらにはサービスの「Q」が駄目になったときには、サービス「P」がその代替を果たせるように冗長化されていました。
ある日、Redisに障害が発生して駄目になりました。インメモリキャッシュが使えなくなって性能の問題は発生しましたがCassandraで処理を続けていました。
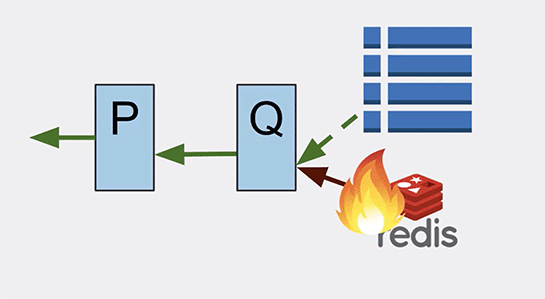
しかしCassandraの性能はどんどん落ちていき、「Q」は十分な速さでCassandraからデータを取り込むことができなくなり、データオブジェクトが見つからないというエラーが発生するようになりました。
「Q」がエラーを起こしたため、処理を「P」が肩代わりしようとしましたが、「P」はデータが削除されない前提で処理をしようとするので、データが見つからないというエラーは「P」にとって矛盾する状況でした。
そのため「P」も立ち往生することとなり、最終的にはオンラインサービス全体が駄目になってしまったのです。
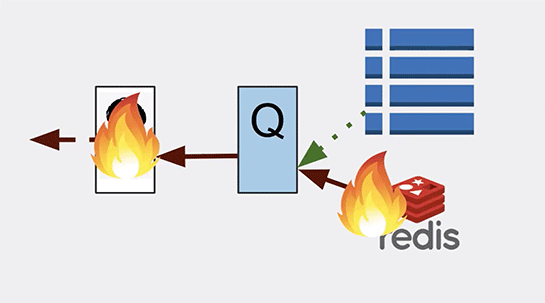
つまり「P」のビジネスロジックが、実際にシステムで起きることと矛盾していた。また、その想定ができなかったことで障害が起きたのです。
PのチームとQのチームは、それぞれ冗長性を備えたサービスを作るような非常に優れたチームでした。
ですから、彼らが同じ部屋にいて、そしてお互いにシステムがこういうふうに駄目になる可能性があるよとコミュニケーションを取っていたら、今回の障害のような順番でイベントが起きたとしても、システム全体が駄目になるということは避けられたのだろうと思います。
事例3:コードフリーズが逆にシステム障害を引き起こす
3つ目、これも小売業の例です。
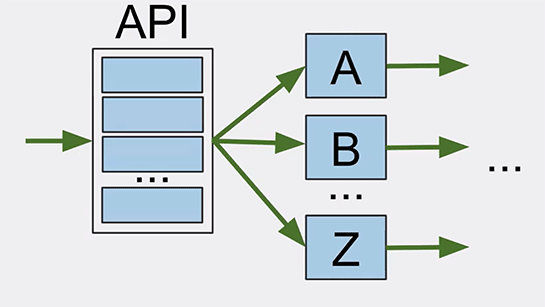
APIのレイヤが、eコマースサイトに入ってくる全リクエストを取り扱っています。
受け取ったら、それをAからZのサービスに送ります。
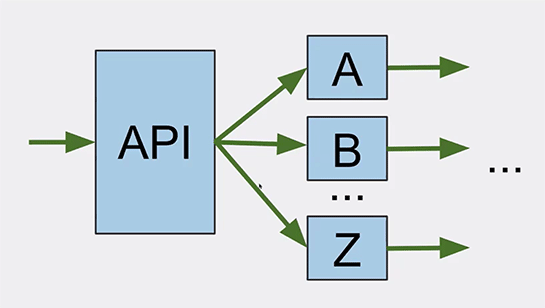
しかしながらこのAPIレイヤは単一障害点でしたので、スケールアウト可能にしました。
さて、11月から始まるショッピングホリデーの時期は、eコマースサイトにとって非常に大事な時期です。
この時期を前にして、この会社はコードフリーズをしました。エンジニアが何か機能を追加したときに間違ってeコマースサイトにダメージを与えることを避けようとしたわけです。
10月末からコードフリーズを開始すると、2週間が経過したところでAPIレイヤのインスタンスの1つがエラーを戻し始めました。
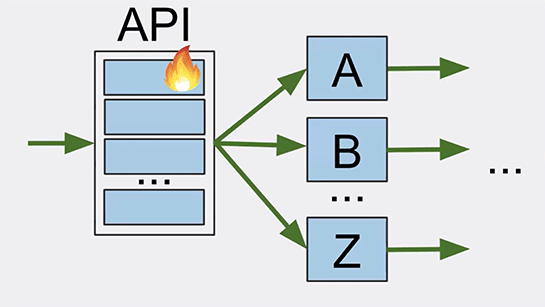
運用チームがそれを発見し、リブートしました。さらにその後数時間の間に、他のノードも全て同じエラーを戻し、相次いでリブートが必要になりました。
このとき、コードフリーズを行っていたので、エラーの原因を探るために監視ツール(Observability:O11y)をいくつかのサーバに導入することにしました。
エラーは金曜日に起きたため、週明けの月曜日にいくつかのサーバに監視ツールを導入し、そのサーバのAPIレイヤを再起動しました。
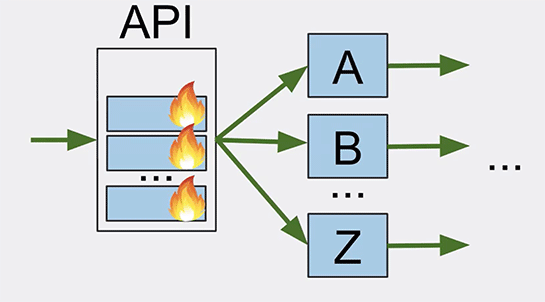
そして何週間か経つと、また同じエラーがAPIレイヤで発生しました。最初に1つのノードでエラーが発生し、その後他のノードでもエラーが発生したため、これらの再起動が必要になりました。
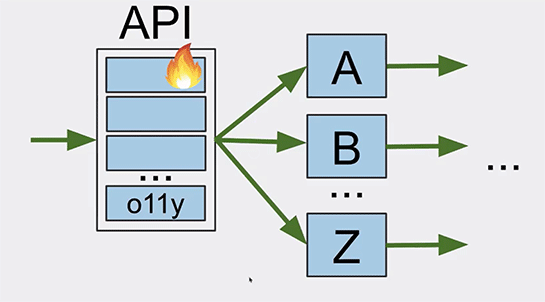
ただし例外がありました。それは監視ツールを入れたサーバのAPIレイヤでした。しかし3日後にはそのAPIレイヤもエラーが出るようになり、再起動が必要になったのです。
何が起こったのでしょうか?
原因としては、何カ月も前に組んだAPIレイヤのJavaコードの中にメモリリークがあったのです。
しかしコードフリーズの前は頻繁にAPIレイヤのコードをアップデートして少なくとも2日に1回は再起動をしていたため、それが発覚しなかったわけです。
そしてロードバランサーでどのAPIレイヤにも同じくらいリクエストを受け取って処理していたため、ほぼ同じタイミングでメモリリークが限界に達してエラーになったのです。
ただし月曜日に監視ツールを入れたサーバだけはほかのAPIレイヤよりも3日遅れでエラーが起こることになりました。
この例から分かるのは、こうした障害を経験したことがなければ、これを予測し、あらかじめテストシナリオに組み込むことは不可能だろうということです。
システムをより安全に運用するためにコードフリーズが導入されたにもかかわらず、それが潜在的に安全性を下げることにつながなるとは、合理的な人であっても予測できなかったでしょう。
複雑なシステムの障害とはそういうものなのです。
個々のすべての要素は100%正しいかもしれない、それぞれの人は望ましい形で行動しているかもしれないけれど、その結果、システム全体としては望ましくないことになるかもしれないのです。

私はこれらのことから、複雑なシステムの可用性について考えるようになりました。こうした直感に反するような振る舞いというのは私にとって非常に魅力的だったのです。Netflixで働くことにしたのも、そのためでした。
≫中編に続く。中編では、インシデントに関わる7つの誤解として、事故を起こす人を排除しても解決にならず、可用性を高めようとするとシステムが複雑になるのは必然であることなどを解説します。