可用性や安全性を高めつつ、ソフトウェアをシンプルにすることは不可能だ。カオスエンジニアリングから継続的検証へ(中編)。JaSST'23 Tokyo基調講演
今回は「可用性や安全性を高めつつ、ソフトウェアをシンプルにすることは不可能だ。カオスエンジニアリングから継続的検証へ(中編)。JaSST'23 Tokyo基調講演」についてご紹介します。
関連ワード (そもそも、安全、爆発等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
Netflixが始めた「カオスエンジニアリング」は、現在では大規模なシステムにおける可用性向上の手法のひとつとして確立し、広く知られるようになりました。
そのカオスエンジニアリングという手法を定義したのが、元Netflixカオスエンジニアリングチームのエンジニアリングマネージャーを務めていたCasey Rosenthal(ケイシー ローゼンタール)氏です。
そのローゼンタール氏が、ソフトウェアのテストに関わる国内最大のイベント「ソフトウェアテストシンポジウム 2023 東京」(JaSST’23 Tokyo)の基調講演に登壇し、「Chaos Engineering to Continuous Verification」(カオスエンジニアリングから継続的検証へ)という講演を行いました。
講演では、カオスエンジニアリングの成り立ちと、従来のテスト手法とカオスエンジニアリングの本質的な違い、そしてなぜ大規模システムにおいてカオスエンジニアリングが欠かせないのか、などが解説されました。
この記事では、その基調講演の内容をダイジェストで紹介します。記事は前編、中編、後編(明日、4月25日公開予定)の3つに分かれています。いまお読みの記事は中編です。
インシデントに関わる7つの誤解
私の会社「Verica」には研究チームがあり、公開されているインシデント情報を収集しており、現時点で1万件以上のインシデントレポートがデータベースとして蓄積されています。
そしてそれをオンラインで全て無料で公開しています。
「VOID」というのは「Verica Open Incident Database」の略です。可用性のインシデントが中心ですが、セキュリティのインシデントも含まれています。
例えば「Redis」と入力すればRedis関連の障害が、「AWS」と入力すればAWS関連の障害を検索できます。
これらのインシデントとインシデント分析データから興味深いことが分かりました。
そこで、インシデントに関わる7つの誤解について紹介したいと思います。
Myth1:Remove the People Who Cause Accidnets
(誤解1:事故を起こす原因となった人を排除する)

1点目は、そもそも事故を起こす人を排除すればよいのではないか、という考え方です。
アメリカの病院ではこれを実際に実行しました。1990年代には、いくつかの病院が医療過誤を起こした医師を排除しました。
というのも、医療過誤の80%は全体の医師の5%にしか関係してないとうことが分かっていたからです。
医療過誤の問題の多くは少数の人たちによって引き起こされているから、その5%をクビにすればいいと考え、彼らを排除すればもう医療過誤の裁判は起きないだろうと思ったわけで。
しかし実際にそれを実行すると、現実には医療過誤の裁判の数が増えてしまいました。
というのも、医療過誤が多い医師は実はスキルが非常に高い人たちだったのです。彼らは高いスキルが求められる、リスクの高い手術をする医師たちでした。
ですから彼らをクビにしてしまった結果、スキルの足りない医師が、本来だったらそのスキルのある医師がやるべき手術をやらざるを得ないということになって、失敗が増えてしまったのです。
複雑なシステム、ソフトウェアでも同じことが起きます。
つまり、より大きな障害を起こす人たちは、実はスキルの高い人たちで、そもそも大きな障害が起きたときに呼ばれるタイプの人たちであるということなんです。
事故を起こす確率というのは、ほぼ誰でも同じなんです。そしてスキルのある人たちの方が実は事故にも関係しやすいのです。
大きな障害とは実は非常にユニークなもの
Myth 2:Document Best Practices and Runbooks
(誤解2:ベストプラクティスと手順書をドキュメント化すればよい)
ベストプラクティスをきちんとドキュメント化して手順書を作れば、それで問題が起こる可能性が減るという考え方、これも直感的には確かにそんな感じがします。
誰かが考えた解決策をそのままやれば治るんだ、という考え方なんですが、それらを作ってる人たちが必ずしも可用性や信頼性についての担当者ではない場合もあるわけです。
大きな障害とは実は非常にユニークなものである、ということです。エンジニアがこれまで見たこともない現象が、壊滅的な障害になりうるのです。
そうしたときに手順書を見ても無駄だった、ということになって、もっと早く別の解決策に時間を使えばよかったということになってしまいます。
根本原因分析は役に立たない(ときもある)
Myth 3: Defend against Prior Root Causes
(誤解3:これまでの根本原因をきちんと直す)

3番目の誤解、これまで起きた根本原因といったものをきちんと直していれば大きな問題は起きない、という考え方です。
例えば、これまで起きたシステム障害の根本原因はこういうことだったから、それを直しておけば同じことは起きないであろう、それによってシステムの可用性は上がるだろうということなんですが。
この問題点は、根本原因の解決でシステムのセキュリティや可用性を上げようとすることそのものが、悪い原因になりうる、ということです。
もちろんこれは議論を呼ぶところですが、ひとつの例を挙げて説明をします。
3年半前の話ですが、ある大手のクラウドプロバイダが数時間のサービス停止に追い込まれました。原因は、エンジニアが構成を変えるためにYamlのファイルを変更したところ、それが原因でシステムの一部がクラッシュしてしまったのです。
Yamlが不適切にパースされて、デプロイメントのルールが全て駄目になってしまい、数時間完全に停止してしまいました。
その後、根本原因分析をして、どのコンフィギュレーションファイルが原因となったのかを見つけ、その中の1行が間違っていて、それを書いたエンジニアも分かりました。
でも、システム全体の可用性を高める上で、その分析情報は何の役にも立ちません。なぜならば誰でも間違いを起こしうるからです。
ソフトウェアエンジニアがミスを犯すということは、もうどうしようもない。「次は気を付けて」と言うしかないわけです。
でも、全員がもちろん気を付けているわけです。もっと気を付けましょうでは、可用性の向上には何の意味もない。
そうではなくて、なぜYamlファイルがこのように書かれ、そしてそれによってなぜクラッシュが起きたのかということを見るべきなんです。
例えば、そのYamlファイルやパーサの書き方が間違っていたんじゃないかということになるわけです。
それは、もしかしたら担当部長がきちんとしたコミュニケーションをチーム間でさせてなかったことが悪かったのかもしれないし、その上役で予算を持っている役員がいて十分に予算を与えなかったからかもしれないし、CTOが可用性を向上させるための時間や予算をもっとかけるべきだったのかもしれません。
根本原因分析というのはエンジニアが問題を起こしたことは発見できるのですが、それとは別に、CTOがちゃんと予算をつけなかったからではないか、といった視点もあるわけです。
システムの一部にその問題の原因をもとめても、可用性を高める点では意味がないということになります。
従って、根本原因を探るだけでは、必ずしも可用性を上げられるわけではありません。
MTTRの長さと障害の深刻度に相関関係はない
Myth 4: Measure Reliability Quantitatively
(信頼性を定量的に計測すればよい)

次は、システムの信頼性を定量的に測ればシステムが改善できる、というものです。
例えば、可用性に関しては「SLAを99%から99.99%にする」といった目標を立てがちです。
あるいは「MTTR」(Mean Time To Repair or Recovery:平均修復時間もしくは平均復旧時間)を短縮すれば、可用性を高められると考えられがちです。
しかし、私たちのVOIDデータベースを見てみると、インシデントもしくはアウテージの時間は正規分布ではなく、指数関数的な分布になっていることが分かります。
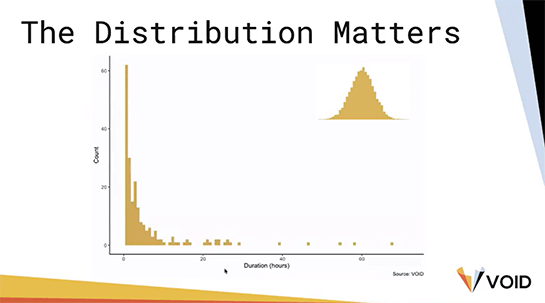
つまりMTTRのテールは長いということで、この平均の数字を小さくしても実際のダウンタイムを小さく出来るかどうかは分かりません。
また、MTTRの長さと障害の深刻度とのあいだに相関関係は見られませんでした。MTTRを短くすると、深刻度は下がるかもしれないし、上がるかもしれない。
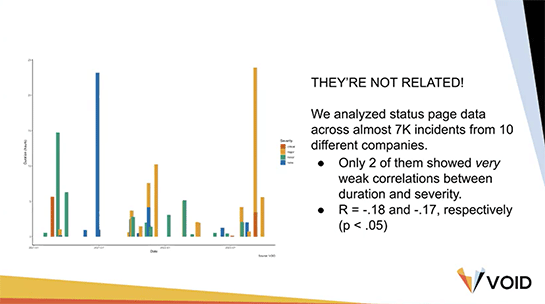
これらの理由やその他の理由で、MTTRの値を見るだけでは、やってることがいいのかどうか、あるいはシステムが信頼性あるのかどうかは分かりませんし、チームの俊敏性が高いのか、効果的なのか、ということもわかりません。

リスクの回避は学ぶ機会を失う
Myth 5: Avoid Risk
(誤解5:リスクを避ける)

リスクを回避すれば安全性が高まる、という考え方もあります。
これは当たり前のように思えるかもしれません。安全に運転がしたければ運転するときにリスクを回避すべきだ、ということです。
しかし複雑なソフトウェアシステムにおいて、意図的にリスクを回避する組織は、基本的にはリスクの対処の仕方をチームが学ぶ機会を回避しているわけです。予想通りのことが起こらなかった場合にどう対処すべきか学ぶことができません。
そこが問題です。
さらに、あらかじめシステムを守ろうとする仕組み、いわゆるガードレールが強すぎると、システムを守る専門家の人たちの対応が難しくなります。
例えば、不用意にクラウド上のノードにログインできないようにすることはセキュリティ的な観点からは正しいのですが、ノードからおかしなエラーが戻ってくるようになった場合、その原因を調査し修正しようとするでしょう。
しかし強力なガードレールがあると、そのための手段を柔軟に考えることが難しくなります。
可用性を高めようとすると複雑になるのは必然
Myth 6:Simplify
(シンプルにする)

システムをシンプルにすれば安全になる、これも一見常識的なように思います。
複雑なシステムは危険であると言われていますので、その複雑性をなくせば、シンプルで安全なシステムになるだろうと考えがちです。
しかしいくつか問題があります。
まず、複雑性には二つの形があります。偶然のものと必然のものです。
偶然のものというのは、何かの仕事の副作用として複雑さが生じる場合です。コードをたくさんを書くことでシステムの複雑性が高まる。その複雑性はある程度下げることができても、ゼロにすることができません。
ソフトウェアエンジニアとしての主な仕事は機能を追加することですので、どうしても複雑性を追加することになってしまいます。それが偶然出てくる。
もうひとつが必然的に生じる複雑性、つまり何らかの機能を満たすためには絶対に生じる複雑性です。
いずれの場合でも、持続可能な形でソフトウェアシステムの複雑性を下げることはできません。できると考えたいわけですけれども、実際にはそうはなりません。
例えば、ソフトウェアエンジニアがデータベースの開発を命じられたとします。
非常にシンプルなキーバリューデータベースで、ノートPCでも簡単に動くものを作りました。

次に、これをもっとセキュアで可用性の高いものにするということで、クラウドに対応させましょうとなりました。
そうなると、データは複数のノードが受け持つようになり、キーリングが採用され、ノードは冗長性を持つ、などということになっていきます。
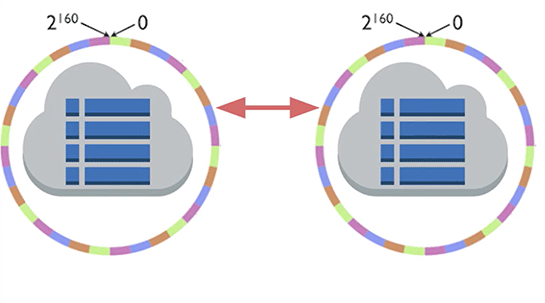
つまりデータベースの可用性や信頼性を高めようとすると、複雑にならざるを得ません。開発を命じた上司が、もっと可用性や安全性を高めつつ、同時にシンプルにもするのだ、と言ったとしたら、そこには矛盾があります。
それは不可能なんです。
より安全なシステム、より可用性の高い、信頼性の高いものは、より複雑性が高くなる、ということが統計でもわかってます。
冗長性がインシデントへ導くこともある
Myth 7: Add redundancy
(冗長性を高めること)

7番目は、冗長性を高めるということ。システムをもっと安全にしたいのであれば、もうひとつコピーを作ろうというわけです。ソフトウェアエンジニアが特にインフラで採用する方法です。
これはスペースシャトルチャレンジャーの写真です。1986年に爆発事故を起こしました。

その原因の解析が行われて、最終的に「Oリング」というゴムのバンドが原因であったということが分かりました。

これがスペースシャトルに使われていた固体燃料のブースターの断面図です。Oリングは2つ使われています。冗長性を持たせようということで2本目が入っていました。
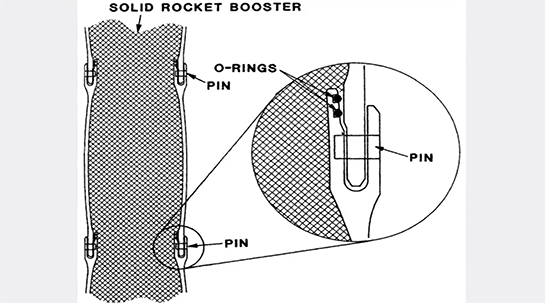
スペースシャトルの2回目のフライトの後、固体燃料のブースターを分析すると、1つ目のOリングに間隙があってそこまで燃料の一部が到達していたということがわかったわけです。
そこで燃料がそれ以上この先へ進まないように、いろんな実験をしました。ただし、その間もスペースシャトルの打ち上げは中止にならず、行われていました。
その理由の1つが、2つ目のOリングがあったから、もう一つ冗長性があるからと考えたためでした。
しかし最終的には爆発にまで至ってしまった。
ですから冗長性を持たせたとしても、それは壊滅的なインシデントになりうる、そこへ導く理由のひとつになりうるということが分かっているのです。
ですから単に冗長性を持たせれば、それでシステムが安全になる、という考え方は間違いだということになります。
≫後編に続く(明日、4月25日公開予定)。後編では、必然的に複雑になるシステムで問題を起こさない方法として、なぜカオスエンジニアリングを用いた継続的検証が重要なのか解説します。