技術的負債を抱えたレガシーコード。変なメソッド名と入り組んだロジック、リファクタリングするならどちらが先?(前編)
今回は「技術的負債を抱えたレガシーコード。変なメソッド名と入り組んだロジック、リファクタリングするならどちらが先?(前編)」についてご紹介します。
関連ワード (対象、発表、記事等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
ソフトウェアの品質をテーマに研究をしている名古屋大学 森崎研究室は、ソフトウェアの技術的負債をなんらかの形で数値化する手法の研究の一環として、コードの読みにくさの原因となる要因などを分析した研究結果を発表するイベントをオンラインで開催しました。
今回発表された研究では、技術的負債を抱えたレガシーコードのリファクタリングで取り除かれた問題の90%以上が、メソッド名と実際の関数の動作が一致していない、あるいは関数名とコメントが矛盾しているなどの「命名的問題」、もしくは複雑で読みにくい多数の条件分岐や深いネストなどを抱えた「構造的問題」のいずれかであるという先行研究があることを踏まえ、どちらを優先してリファクタリングすると保守性や可読性が高くなるかを調査しています。
具体的には、命名的問題が含まれたJavaコードと構造的問題が含まれたJavaコードをそれぞれ用意し、2つに分けたプログラマのグループにそれぞれのコードを読解してもらうことで、どちらの読解が難しかったか、時間がかかったか、などを分析したものです。
イベントの前半は、森崎研究室 井上祥太郎氏による研究内容と結果の発表が行われ、後半には森崎研究室の森崎修司氏の進行で、この研究に参加したタワーズ・クエスト株式会社 和田卓人氏による解説や考察が行われました。
この記事ではそのダイジェストを紹介します。記事は前編と後編の2つに分かれています。今お読みの記事は前編です。
命名的問題と構造的問題の2つのコード
森崎研究室 井上祥太郎氏が、まず今回の研究内容と研究結果について以下のように報告しました。
井上氏 参加者の皆さんに読解していただいたコードは「CommunicationChannel」というもので、データパケットを転送するための接続を確立し、データ圧縮、暗号化、ローディングをオンにすることができるライブラリです。
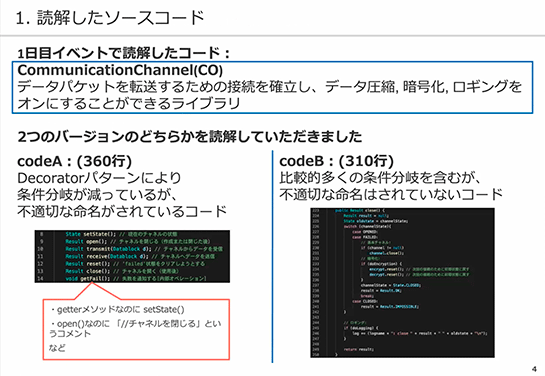
「CommunicationChannel」のコードは、2種類用意しました。
「codeA」はDecoratorパターンを採用しており、条件分岐は減っていますがコード中に不適切な命名があります。
例えば、getterメソッドなのにsetState()と命名されていたり、open()というメソッド名なのに「//チャネルを閉じる」というコメントがついていたりする、などです。
これはレガシーなコードでよく見られる「命名的問題」を含むコードを模しています。
一方、codeBはレガシーコードでよく見られる「構造的問題」を模しており、複雑で読みにくい多数の条件分岐や深いネストなどの問題を抱えています。ただし、不適切な命名はされていません。
読解してもらうプログラマへの事前アンケート
続いて、エントリーいただいた方々をcodeAとcodeBを読解するそれぞれのグループに同じように振り分けるために、事前にお答えていただいたアンケートの内容を紹介します。
アンケートで収集したデータは、例えばJavaの開発経験年数であったり、プログラミング能力の自己評価であったり、Decoratorパターンに関する知識やレガシーなコードの読解経験などです。
以下がアンケートの結果です。
左が、Javaの開発経験年数の分布です。横軸が年数で、縦軸が人数を表しています。経験年数は若干0年から5年に多めに偏ってはいますが、おおまかには全体に分布しています。経験年数を平均すると7.9年で、最小は0.5年でした。
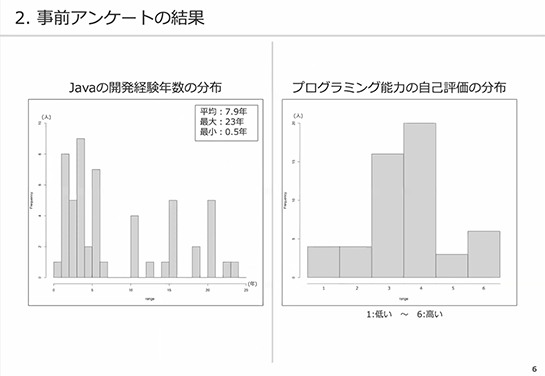
右は、プログラミング能力の自己評価の分布です。1だと自己評価が低く6だと高くなります。縦軸は人数を表しています。中間の3~4が多く、最高評価の6も若干多い分布になっていました。
次の図、左はDecoratorパターンに関する知識の分布です。こちらも横軸の1~7の値でDecoratorパターンに関する知識の多さを自己評価してもらっています。
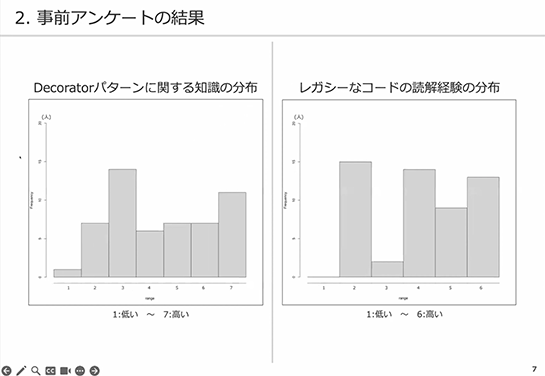
右はレガシーコードの読解経験の分布です。同様に1は経験が低く、6は多いとなっています。
プログラマを2つの均質なグループに振り分け
この事前アンケートのデータを基に、エントリいただいたプログラマの方のDecoratorパターンに関する知識と、レガシーな行動の読解経験がcodeAを読解するグループ(グループA)とcodeBを読解するグループ(グループB)で均質になるようにグループ分けをしました。
codeAを読解するグループが26名、codeBを読解するグループBが27名でした。
そしてcodeAまたはcodeBを読解いただいた上で、10問のクイズに回答していただきました。
クイズの内容は、コードの読解精度を測るために、メソッドの呼び出しの返り値がある特定の値を持つときの条件であったり、コードを変更した場合に、更なる実装の変更が必要となる箇所の回答であったりというようなものでした。
読解にかかった時間や、読解の難しさについての意見などについても記入していただいています。
読解精度には「命名的問題」の方が悪影響
読解後のクイズの正答率について。
正答率については有意水準5%で統計的に有意な差がありました。
これ以降の「統計的に有意な差」も有意水準5%で調べています。「有意水準5%で統計的に有意な差がある」ことは、大まかには次のようなイメージです。2グループの数値に差があるときに、対象の2グループに本質的な差がある場合と本質的な差はないけれど、たまたま差があるように見える場合があります。有意水準5%で統計的に有意な差があることは、偶然でこの差が出るのは5%未満ということを指し、偶然とは考えにくいということを指します。なお、差があることのみを確かめる方法なので、2グループの差が大きいことを表すとは限りません。
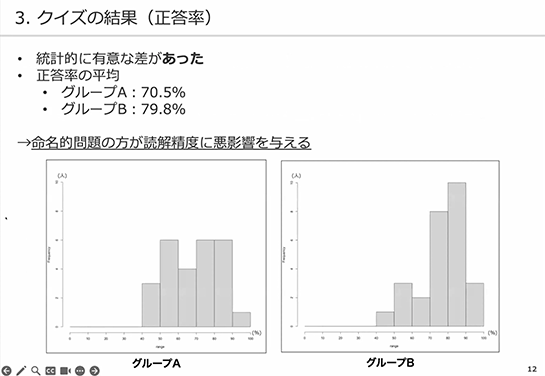
正答率の平均はグループAが70.5%で、グループBが79.8%です。上の2つの図が正答率の分布を表しています。横軸が正解であった回答の割合(正解率)で0%から100%まで、縦軸が人数です。
ご覧の通り、グループBの方が、正答率が高い方に偏っているということが分かります。
このことから、読解精度には命名的問題の方が悪影響を与えると結論づけられます。
読解時間について有意な差はなし
井上氏 続いて読解時間についてです。読解時間については、グループA, Bの間に統計的に有意な差があるとは言えませんでした。
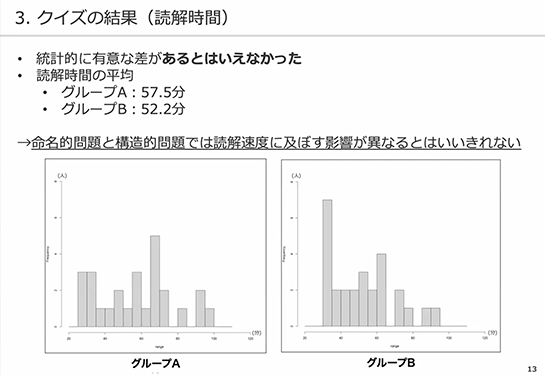
グループAの読解時間の平均は57.5分、グループBの平均は52.2分となっておりまして、やはりグループBの方が短い時間で回答ができているというような状況です。
グラフを見ると、グループBの方が時間が短い方にやや偏っているようです。
ただ統計的に有意な差はありませんでした。この差は(5%以上の確率で起こる)偶然かもしれないので、結論としては命名的問題と構造的問題では、読解速度に及ぼす影響が異なるとは言い切れない、となりました。
「構造的問題」の方が読みにくさを感じた
クイズに回答後、事後アンケートにも回答していただきました。
まず最初に、今回の読解コードは、普段読んでいるレガシーコードに比べてどのくらい読みにくかったかを回答いただきました。
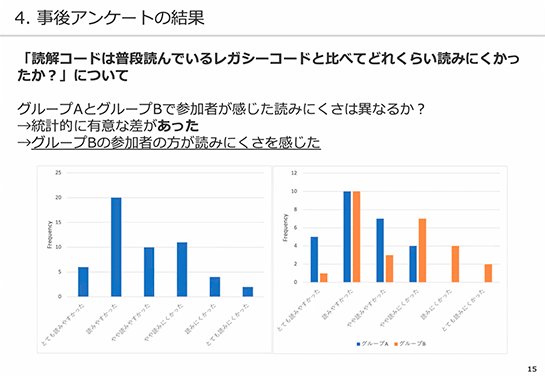
図中の左のグラフ(青い棒グラフ)は全体の分布を表しています。全体としては「読みやすかった」方に偏っているように見えます。
右のグラフ(青とオレンジの棒グラフ)は、グループAとグループBで、参加者が感じた読みにくさが異なるかを示す棒グラフで、青の棒がグループA、オレンジの棒がグループBの人数を表しています。
オレンジのグループBの方が、読みにくい方に偏っていることが確認できると思います。4段階の読みにくさを「読みにくい」「読みやすい」の2段階に変換したところ、その偏りは統計的に有意なものでした(その偏りが偶然起こる可能性は5%未満)。
このことから、結論としてグループBの参加者の方が読みにくさを感じたということが言えます。
「命名的問題から修正すべき」が多数派
続いて、その他のアンケートの項目で、構造的問題と命名的問題のどちらから修正すべきだと考えるかを集計した結果を紹介します。

「構造的問題から修正すべき」派が14名、「命名的問題から修正すべき」派が39名いました。
「命名的問題から修正すべき」が多数派となりました。
構造的問題から修正すべき派の意見としては、「致命的なバグは構造的問題から生まれやすいと考えているから」「命名的問題は読んでいるうちに慣れてくるが、構造的問題は、慣れないから」「命名的問題の修正には時間がかかるため、手のつけやすい構造的問題から」などの意見がありました。
命名的問題から修正すべき派の意見としては、「リネームとコメント追加くらいなら動作に影響がないから」「構造的問題は局所的に起こるが、命名的問題はコードのどこにでも出てくるものがあるため」「構造的問題はどこから修正したらいいかわからないケースがあるため手のつけやすい命名的問題から」などの意見がありました。
特に各意見の3つ目で、人によって手のつけやすい問題が異なっている、という点も注目すべきポイントかなと思います。
リファクタリングで「読みにくさ」を頼りにするのは要注意
最後にまとめをさせていただきます。
統計的に有意な差があったのは、グループA(命名的問題)より、グループB(構造的問題)の方が正答率が大きいということ。一方でグループA(命名的問題)よりグループB(構造的問題)の方が読みにくさを感じた、という点です。
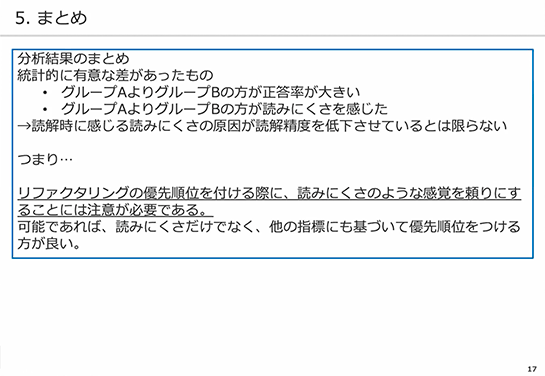
つまり、読解時に感じる読みにくさの原因が、読解精度を低下させているとは限らない、ということが分かります。
ですので、リファクタリングの優先順位をつける際には、「読みにくさ」のような感覚を頼りにすることには注意が必要である、と言えます。
可能であれば「読みにくさ」だけでなく、他の指標に基づいて優先順位をつける方が良いかと思われます。
≫後編に続く。後編ではこの結果についての考察、なぜレガシーコードに問題が積み重なっていくのか、などが語られます。
関連記事
- 品質を犠牲にすることでソフトウェア開発のスピードは上がるのか? 和田卓人氏による 「質とスピード」(前編)。デブサミ2020
- 東証がSREによるレジリエンス向上に挑む理由。過去のシステム障害から何を学んだのか?(前編) ソフトウェア品質シンポジウム2022
- グーグルはコードの品質向上のため「バグ予測アルゴリズム」を採用している
- 4年後までにソフトウェアテストの70%を生成AIが作り、コードの品質は向上するようになるとの予測、IDC