世界中のITエンジニアが悩まされている原因不明でテストが失敗する「フレイキーテスト」問題。対策の最新動向をJenkins作者の川口氏が解説(後編)。DevOps Days Tokyo 2022
今回は「世界中のITエンジニアが悩まされている原因不明でテストが失敗する「フレイキーテスト」問題。対策の最新動向をJenkins作者の川口氏が解説(後編)。DevOps Days Tokyo 2022」についてご紹介します。
関連ワード (修正、知見、解決等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
世界中のITエンジニアが悩まされている問題の1つに、テストが原因不明で失敗する、いわゆる「フレイキーテスト」があります。
フレイキーテストは、リトライすると成功することもあるし、失敗する原因を調べようとしてもなかなか分かりません。GoogleやFacebookやGitHub、Spotifyといった先進的な企業でさえもフレイキーテストには悩まされています。
このフレイキーテストにどう立ち向かうべきなのか、Jenkinsの作者として知られる川口耕介氏がその最新動向を伝えるセッション「Flaky test対策の最新動向」を、4月21日、22日の2日間行われたイベント「DevOps Days Tokyo 2022」で行いました。
セッションの内容をダイジェストで紹介しましょう(本記事は前編と後編で構成されています。いまお読みの記事は後編です)。
フレイキーテストがあったとしても、つつがなくデプロイするには
まず、つつがなく変更をプロダクションに送り込むにはどうするか。一番多くて無難な方法は、やっぱり単純にリトライすることです。
とにかくフレイキーネスはランダムに起こるのだから、失敗しても次は成功するかもしれない。あらゆるビルドツールとかテストランナーにこれはついてる気がします。
これはGradle用、次がMaven、これはJenkinsのプラグインで、どれもフレイキーテストをリトライする仕組みです。こうして見てみると、リトライと一口に言っても実はいろいろあるのだなと感じました。
GitHubとDropboxでは、VMとかコンテナを使ってシステムクロックを別な時間に強制設定して走らせることをしているそうです。
先ほど、時間に起因してテストが失敗することが多い、という話をしましたが、それなら時間を強制的に変えたら失敗しなくなるだろう、あるいは別のVMにして環境をごっそり変えた方がフレイキーネスなテストは成功しやすいだろうという考えですね。
こういうシステムを作るのはそれなりの労力が必要なので、彼らは頑張って作ったんだろうなと思います。
こうして見ると、小さいリトライループから大きいリトライループまでいろいろあるんだなと。フィードバックループの大きさみたいなものがケースによってだいぶ違うように感じられました。
リトライによってフレイキーネスを隠してしまうという課題
リトライはよく使われている手法ではあるのですが、この手法にどういう問題があるかというと、1つにはフレイキーネスを隠してしまう、ということですね。
いろんなDevOpsエンジニアが感じていることだと思うんですけど、隠すという事に心理的な抵抗が発生して、リトライみたいな手法を使いたくないと思う人たちがいる。そういう人はフレイキーネスでテストに失敗したら、そこでエラーが起きたことにしてパイプラインを止めてしまう。
すると、毎回デベロッパーの人が明示的にチェックに入らないといけなくて、毎回苦労するデベロッパーとDevOpsエンジニアとの軋轢がそこで発生する、みたいなことがあります。
だからやっぱりそのフレイキーネスを計測するための手法として、エラーを起こす、というのはあまりよくないなと、僕は思うようになりました。
もう1つの問題は、リトライをすると単純にテストの実行に時間がかかるようになるんですね。本当にコードに問題があってテストに失敗する場合でも、リトライを何回もやってそれが全部終わるまでは結果がデベロッパーのところに来ない。
例えば、何かの統合テストの中で一件のテストに10分かかるとすると、それを10回リトライすればそれだけで1時間かかることになるので、時間のかかり方は馬鹿にならないということが言えると思いますね。
フレイキーな失敗をシステマチックに無視する
リトライ以外にも、もう少し凝ったことをやってる人たちがいて、それが面白かったので紹介します。
それはもう少しシステマチックにフレイキーな失敗を無視するという手法です。例えばDropboxやGoogleがやっていたプリマージ(開発者に近い一番頻繁に実行されるテスト)という手法では、フレイキーネスのせいで起こった失敗であればスルーする。つまり、開発者の間近ではフレイキーネスでテストが失敗してもマージは許すということです。

これは思い切った決断だなと思います。
その代わりにメインブランチにマージされてから、ポストマージでもテストを実行する。その場合、テストの実行結果は開発者の人たちが直接見るわけじゃないので、そこでフレイキーな失敗が起きてもどう処理するかはまた別に考えることが出来ます。
テストに関して進んでいると思われる人たちにも、フレイキーテストは受け入れざるを得ないんだ、という態度が感じられます。
ビルド職人たちと話していてよく感じるのは、やっぱりフレイキーネスはダメですという原理主義的な人たちは一定数いて、彼らはフレイキーネスはダメだからそれを隠すのもイヤだと考えていて、開発者がそのフレイキーネスによって起こるテストの失敗の痛みを直接感じれば、それがモチベーションになってフレイキーネスを修正するのではないかと、こういう考え方をしてる人が結構います。

これは気持ちは分かるのですが、あんまり現実的ではないかなと僕は思うようになりました。
なぜこれが現実的ではないと思うかというと、例えば同じ開発チームのメンバーであっても自分ではない別の人の作ったフレイキーネスのせいで自分がコードを変更しなければならないのは耐えられない、ということが往々にして起こるんですね。
DevOpsエンジニアは、開発チームがフレイキーネスによる痛みを直接感じないとフレイキーネスを直してくれないだろうと考えるのですが、開発チームの個々のデベロッパーにしてみたら、そこは別に自分のせいじゃないし、となる。だからDevOpsエンジニアが考えるようなインセンティブはその通りには機能しないのではないかと、僕は思います。
こうした点についてはみんなが一家言持ってると思うので、皆さんはどう思ってるのかが僕には興味深いし、ぜひ話を聞いてみたいなと思っています。
フレイキーネスをどう計測するのか
ここまでは、フレイキーネスが存在するにもかかわらず、つつがなくビルドをしていくにはどうするか、という話でした。
ここからは次の章に移って、フレイキーネスをある程度受け入れるとしたら、それをどう計測するのか、についてです。
これについていろんなチームがどういう取り組みをしてるかというと、普通のやり方とは結局のところ、長く同じチームにいるエンジニアはどのテストがフレイキーなのかをなんとなく知っている、という状態が多いですよね。
だから新しくチームに加わった人なんかは、テストが失敗したと思ったらシニアエンジニアみたいな人から、そこのテストの失敗は気にしなくていいよって言われて、いやそんなの知るかと、そういうことが起こる。
これがやっぱり多い、圧倒的に多いと思います。
逆に言えば、みんなそのくらいしかまだやってない状態なんです。
それより一歩先に進んでいる開発チームはどういう取り組みをしてるかというと、多いのは、同じコードに対してテストを何回も実行したとき、その結果が違っていればそれをフレイキーとみなす、という方法。
これは非常に素直に定義に従っている気がします。Googleも同じような考え方でフレイキーネスを計測していましたし、我々の会社でもフレイキーネスを解析するときはこういう方法で計算しています。

これは簡単だから「ベースライン」と呼んでいるのですが、問題もあります。
例えば、外的要因、例えばたまたまネットワークが落ちているせいでテストがまとめて失敗する、みたいなことが起こるじゃないですか。
それに気がついた誰かがネットワークを復旧させて再びテストを実行したら通りました、というのはよくあるパターンです。けれどこの方法だとこのテストはフレイキーだと観測してしまいます。
つまりベースラインではテストに内在する問題と環境要因による失敗を区別できない、みたいなことが起こる。
その中で目を引くことをやっているチームはいくつかあって、Spotifyの例が面白かったんですけど、彼らは「フレイキーネスはランダムで起こるから、複数のテストでまとめて失敗が起きているときは多分フレイキーじゃないよ」と言ってるんですね。なるほどねと、確かにそんな気もするなと。
これは縦方向にテスト1、テスト2、テスト3とテストの実行結果を並べて、それを日付順に横方向に並べています。
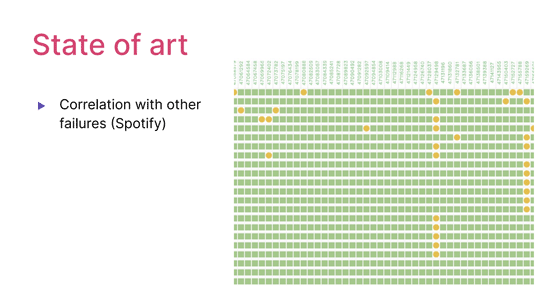
これを見ると、縦方向にまとめて失敗しているテストは多分フレイキーによる失敗じゃないなと。一方でポツポツ失敗しているテストはフレイキーっぽいという指摘をしています。
さらにFacebookでは、なんかすごい、Ph.D.とかを雇ってこの問題を解決させようとするとこうなるんだなというのをすごく感じるんですけど、ベイズ推論というアプローチを使っているそうです。
テストを走らせたら、ある一定の確率(Pb)でそのコードが悪かったから、つまり本当にテストに問題があったからテスト失敗する、という「良い種類の失敗」がありますと。
一方でコードは悪くなくて、ランダムにフレイキーネスがあったせいでテストの失敗が起こる可能性(Pf)もあります。
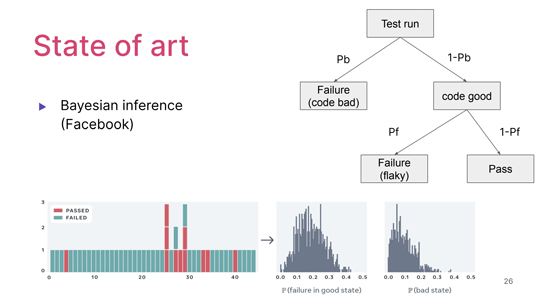
どっちでもなければテストは成功するけれど、人間には失敗したときのこの2つは区別できなくて、どちらも失敗として観測される。でも隠れた変数が2つありますよ、みたいな。
このPbとPfを、テストの実行結果だけを見て推定する、確率を求めるちょっとした算数があるんです。そういうのを使って推定する。
人間の直感をちゃんと数学的に、大げさな数学を持ち出してモデル化するのは、いかにもFacebookっぽい。こういうことをやってる人たちもいるわけです。
計測したフレイキーネスを問題解決にどう活かすのか
こうしてフレイキーネスを計測する目的は何かというと、人間の注意をそこに振り向けて問題を解決していくためです。そこはどうなってるのか。これがこれからお話しする3番目の柱ですね。
そこで普通の人たちは何をやってるかというと、大体はそのチケットをファイルして、デベロッパーの人に見てもらって、直すか、そのテストを飛ばすか、場合によってはそのテストを捨てるということです。
いろんな人と話してて感じるのは、テストを捨てることに対してみんな心理的な抵抗が非常にあるように感じるんです。これは非常に興味深くて、というのはフレイキーな失敗って嫌じゃないですか。
本当にテストがフレイキーだとしたら、その中には直せないものもあるわけで、そうしたテストは捨てた方が全体としてよい場合がたくさんありそうな気がするんです。でも、テストを捨てるということは思ったほどには行われてない印象です。なぜなんでしょうね。
そういうナイーブな視点から一歩先に進んでる人たちは、このフレイキーネスがどのぐらいのインパクトを及ぼしているのかについて凝ったアプリを作っています。これは画面から分かるようにGitHubの話ですけど、インパクトスコアみたいなのを計算してるんですよね。
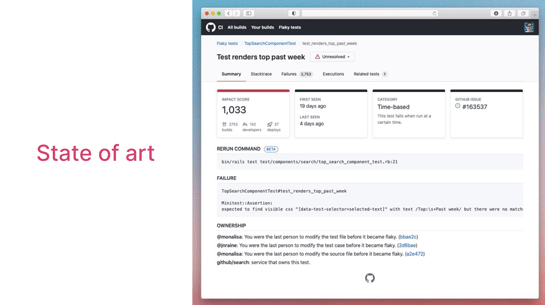
これによるとフレイキーネスのせいで2753のビルドに影響があり、140人が迷惑した、ということが書いてあるんです。
これで何をやろうとしてるかというと、どのテストのフレイキーネスを修正する必要があるのかを定量的に調べよう、という試みですよね。
少数のテストが非常に大きなインパクトがあるのであればそこを直すべきで、他のところには注意を払うべきではない、ということですね。
もう1つは、リトライの過程からフレイキーネスの原因について、推定をする。例えば、テストの実行時間を変えるとフレイキーネスが直ったり再現したりすることが分かれば、原因がタイムベースではないか、ということを推定すると。
あとは、この誰がこのコードを最後にいじったかとか、そういう情報を出して問題の解決にあたるデベロッパーの手助けをしようとしている。
普通の会社はなかなかここまでできないと思いますが、進んでいるチームではここまでやってることが驚きです。
Dropboxでも自動化が進んでいて、テストはまずデフォルトでは「ヘルシーテスト」に分類されるらしいんです。
そしてテストが失敗したら「ノイズジーテスト」と分類されて、ノイジーだと判定されたテストはシステムが自動的に再実行したり前後のバージョンをもう1回テストし直したりして、テストがフレイキーなのか、あるいはテストが壊れているのかを推定しようとするんです。
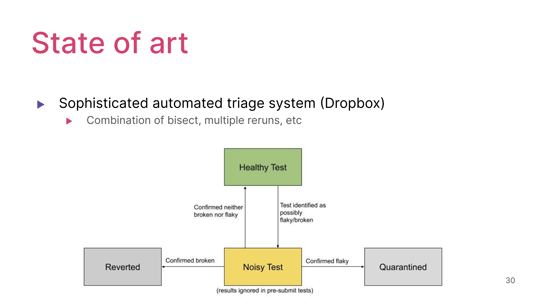
その結果によって、テストの結果はレジメイトで変更したコードが駄目そうだということになったら投入された変更を自動的にリバートして、逆にテストに問題があるということだったらそれをクアランタイン(検疫)と言って、そのテストが実行されないようにする、みたいなステートトランジションをシステムで自動的にやっていて、かなりのことが自動的に究明される状態になってる、ということらしいです。
これに類する3分類をやってるチームは他にも見たことがありますし、どれだけ凝った自動化をしているかは別にして、自動的にある種のフレイキーの分類をする取り組みも、あちこちでやられてるように感じられました。
こうすることで、人間が注意しなくてはけないものの数を減らす、という取り組みですね。
これだけ一生懸命いろいろ作って、でも結局クアランタインの仕組みは、テストを削除をするのが嫌だから削除ではないのだけど事実上削除された状態にする、ということですよね。これって何か、削除したくないんだけど実際は削除したい、バナナはおやつじゃないからバナナは食べていいみたいな、そういう自分をだます方法として使われてるだけなんじゃないか、という気がちょっとしています。
アーキテクチャ的な工夫でフレイキーネスを解決していく
この3つの柱のどれにも入らないんですけれど感心したアプローチがいくつかあったので、それを紹介すると、これはAirBnBがモバイルアプリをどうやってテストするかという話をしています。
モバイルアプリの開発をしている方は分かると思いますが、フレイキーネスがどうしても入りやすい。外部のシステムに依存したりするから。

- Better Android Testing at Airbnb — Part 1: Philosophy and Mocking | by Eli Hart | The Airbnb Tech Blog | Medium
この問題を本質的に解決するためには、アプリケーションのアーキテクチャ自体を変える必要があるという結論に彼らはたどり着いた。
そのためにそのフレームワークを自作するんですよ、という話をしています。
こういう製品開発のエンジニアリングとQAとが融合することによって、よりもっと本質的な解決方法が模索されるというのは最上のものだと思うので、そういうことが実行されるのは素晴らしいことだと思います。
僕の身近な範囲では、Javaではもうだいぶ前にサーバーサイドはIoCコンテナ、ディベンデンシーインジェクションみたいなのを使う書き方が流行ったのもテスタビリティが大きな要因の1つですよね。
そういった、テストはフレイキーなんだってことを受け入れて何かするんじゃなくてアーキテクチャ的な工夫をする事でフレイキーネスを取り除けないか、という取り組みは非常に尊いなと僕は思いました。
これからどうなっていくのか。2つの方向性
こういういろんな人たちの取り組みを見て、これからどうなっていくのかについて考えると、2つの問題に分割されていくのかなと。
1つは、任意のテストを、任意の対象に走らせる、という機能。それが基盤にあると、後で触れるような何かいろんな処理ができるようになる、というのが明らかな流れだなと思いました。
今はビルドとテストが分離されてないビルドプロセスが結構多いんですよね。
これを工夫して、ビルドして、その結果を後で再利用して任意のテスト走らせられる環境になっていると、それを使ってフレイキーネスの計測をはじめとしたいろんなことが可能になりそうだなっていうことが、感じられました。

これはビルドプロセスをいじらないとできないことだから、個々のチームがやる必要があります。
もう1つは、実際にたくさんの実行されたテスト結果から何かの知見を引き出す。あるいは知見を引き出すためにはこのビルドにこのテストをもう1回走らせる必要がある、みたいな、そういう目や頭脳としての判断をする部分があって、いろんなチームの取り組みを見てると、ここは環境にあまり依存しない部分だなって感じるんです。

この部分で汎用のものを作ると、いろんな人が全社の機能と組み合わせていろんな人の環境でうまくフレイキーネスとかに対処できるシステムができていくはずで、これから世の中がそういうふうになっていったらいいなと、そういうふうにしていこうと僕は思っています。
まとめ
ということで、まとめです。
フレイキーネスはあちこちに本当にあまねく普遍的に存在してる問題なのでいろんな人が取り組んでいて、その取り組みには3つの柱があります。
1つ目は、粛々と変更をビルドし、エラーを隠して問題なく変更をプロダクションに送る。2つ目はそれでマスクされるフレイキーネスを定量的に計測しましょうよという話。3つ目は計測されたもののうち必要なものをフィードバックしていくということ。
テストをいろんなビルドに対して実行する機能はCI環境に作り込んでいくべきだけれども、その結果をどうやってコードに反映させるか、その仕組みについては、それぞれ自分のところで作るよりもいろんな人と力を合わせたほうがよさそうだなと考えているところです。
私のセッションは以上になります。ありがとうございました。
関連記事
ソフトウェアテストの自動化を推進する方法については、下記の記事もぜひご参照ください。
- 「アジャイルサムライ」の著者が語る、技術志向の企業が世界をどう見ているのか? そしてソフトウェアテスト自動化を進化させる方法について(前編)。JaSST’22 Tokyo基調講演
- 「アジャイルサムライ」の著者が語る、技術志向の企業が世界をどう見ているのか? そしてソフトウェアテスト自動化を進化させる方法について(中編)。JaSST’22 Tokyo基調講演
- 「アジャイルサムライ」の著者が語る、技術志向の企業が世界をどう見ているのか? そしてソフトウェアテスト自動化を進化させる方法について(後編)。JaSST’22 Tokyo基調講演