世界中のITエンジニアが悩まされている原因不明でテストが失敗する「フレイキーテスト」問題。対策の最新動向をJenkins作者の川口氏が解説(前編)。DevOps Days Tokyo 2022
今回は「世界中のITエンジニアが悩まされている原因不明でテストが失敗する「フレイキーテスト」問題。対策の最新動向をJenkins作者の川口氏が解説(前編)。DevOps Days Tokyo 2022」についてご紹介します。
関連ワード (事故、定量的、補完等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
世界中のITエンジニアが悩まされている問題の1つに、テストが原因不明で失敗する、いわゆる「フレイキーテスト」があります。
フレイキーテストは、リトライすると成功することもあるし、失敗する原因を調べようとしてもなかなか分かりません。GoogleやFacebookやGitHub、Spotifyといった先進的な企業でさえもフレイキーテストには悩まされています。
このフレイキーテストにどう立ち向かうべきなのか、Jenkinsの作者として知られる川口耕介氏がその最新動向を伝えるセッション「Flaky test対策の最新動向」を、4月21日、22日の2日間行われたイベント「DevOps Days Tokyo 2022」で行いました。
セッションの内容をダイジェストで紹介しましょう(本記事は前編と後編で構成されています。いまお読みの記事は前編です)。
Flaky test対策の最新動向
ご紹介にあずかりました川口です。今日はフレイキーテストの話をしようと思います。

フレイキーテストについては皆さんすでにご存知ではないかという気がするんですけれども、実際にGoogleの人が書いたこの論文(「Flaky Tests at Google and How We Mitigate Them」)によると、実になんと7つテストがあるとき、その1つには何らかのフレイキーネスがあると。それぐらいフレイキーテストはあちこちで起こっている問題です。

ITエンジニアの皆さんだったら、そんなこと言われなくても知ってるよっていう感じになるんじゃないのかなって思うんですよね。っていうぐらい、どこの開発チームでもフレイキーネスの問題には苦しんでいるかなと僕は思います。
僕自身はJenkinsを作る前はサン・マイクロシステムズでコンパイラを作っていました。コンパイラは挙動が決定的で、ある入力に対して必ず決まった挙動があるのでフレイキーネスとは無縁な世界だったんです。シングルスレッドだったし。
でもそれは本当にソフトウェア開発の現場では限られた非常に幸運な環境で、その後のJenkinsは立派なマルチスレッドアプリケーションだし、いろいろ複雑なシステムなので、どうしたってこのフレイキーネスの問題を避けることができなかったという記憶があります。
そういうこともあって、このフレイキーテストの問題に世界中のエンジニアリングチームはどういうふうに取り組んでいるのかなということを調べました。そして分かったことを発表する、というのがこのセッションの内容になります。
フレイキーテストの何が問題なのか?
まず最初にスタート地点として確認なんですが、なぜフレイキーテストが良くないのか。狼少年効果みたいなのがやっぱり一番スタート地点かなって思うんですよね。
要するにフレイキーなテストっていうのは、本当はコードには問題がないんだけどテストが失敗するっていうことだから、火事が起きてないのに鳴る非常ベルみたいな、そういうことかなって思います。
僕は中高のとき男子校だったんですけど、非常ベルを誰かがいたずらしたり壊してよくベルが鳴っていて、みんな慣れてくるとベルが鳴っても誰も避難しなくなるんですよ。
もしあの学校で火事が起きたら、みんな逃げ遅れて死んでたんじゃないかって、いまは思います。狼少年効果ってやっぱり危険なんだなと。
ソフトウェア開発の場合、狼少年効果がCIプロセスとかデリバリーパイプラインの中で起こると、そのデリバリーパイプライン全体に対する信用がやっぱり毀損(きそん)されることがあると思うんです。
つまりみんながデリバリープロセスの結果を信用しなくなって、自分で何か別なことを始めるという。さらに管理しているDevOpsチームに対する信頼まで失われてしまうと、彼らが何をやってもうまくいかなくなっちゃう。
そういう危機感があるから、あちこちでリリースエンジニアリングとかビルドエンジニアとか、ビルド職人をやってる人たちはフレイキーネスの問題に敏感にならざるを得ない。
開発者個々人にとってもフレイキーネスのせいで苦しめられた経験があるのではないかと思います。
いろんな人に聞いたよくある話は、帰り際にコードに変更を入れてビルドとテストを実行したら、テストが通るはずなのに通らない。それで仕方がないから家に帰って夜遅くに会社のマシンにログインし直して、テスト結果を確認してからマージしなきゃいけないみたいな。
そういう追加の作業が予期せぬ形で発生するんですよね。
フレイキーテストはただテストが理由もなく失敗するみたいな話をしましたが、逆のパターンもありますよね。本当はテスト対象のソフトウェアに問題があるのだけれど、テストではその問題が滅多にしか発見できないという。例えば、レースコンディションとか。
レースコンディションは、まれに起こるコンカレンシーに関連する問題ですが滅多に起こらない。でも本番環境ではときどき発生する。そういう問題がテストをすり抜けてしまうと、お客さんに迷惑がかかったりユーザーに迷惑かかったりする。
こういうことがあるのでフレイキーなテストはできるだけ解決したい。冒頭で言ったように、もう本当にあらゆるソフトウェアチームがこの問題に悩まされているんです。
だったら皆んな、この問題にどうやって対処してるのか、という話がこのセッションのメインです。
フレイキーテスト、フレイキーネスとは本当はどういうことか?
最初に「敵を知り己を知れば百戦危うからず」じゃないですが、フレイキーネスについてどういうことが分かっているのか。実はいろんなチームの人たちがいろんな発表をしています。
これは先ほど紹介したGoogleの論文からですが、彼らが発見したのは、テスト時に使用されるメモリの量とフレイキーネスの間には有意な相関がある、という点です。これは直感的にはまあそうだろうなって思うじゃないですか。
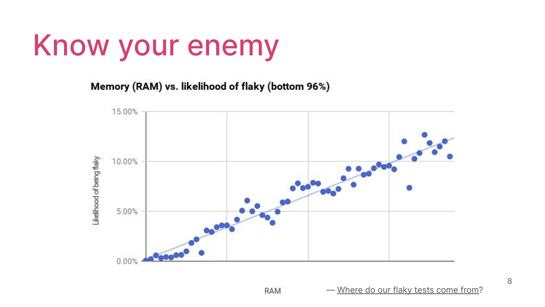
フレイキーテストはシステムを全体としてテストしたときによく起こる挙動で、ユニットテストだとあまり起こらないですよね。だから全体のテストではメモリもたくさん使うはず、ということは言えるけれど、こうやって定量化されると、それを使っていろいろ言えることが増える。だから、これはやっぱり素晴らしいGoogleっぽい発見だなと思いました。
これは確かGitHubかマイクロソフトが言っていた話ですが、フレイキーネスの発生にはいくつかのよくあるパターンがあって、そのひとつは時刻に関連するもの。例えば、月の終わりとか始めとか、バウンダリをまたぐときには問題が起きやすいと報告されていました。
それからグローバルなステートにアクセスしたりするテストだと、予期しない形でシステム全体の状態を変えるので、後続のテストがその状態とぶつかって事故が起こって、どっちかのテストが死ぬみたいな、順序依存性が生まれるみたいなのも、実際にあちこちで体験したことがありました。
これも複数のエンジニアリングチームが言ってるんですけど、テストのフレイキーさは非常に偏って存在している。冒頭で紹介したGoogleの論文によると、7つのテストのうち1つにはフレイキーネスがあるという指摘の一方で、同じペーパーの中では実行されたテスト(テストラン)のうち1.5%しかフレイキーじゃない、とも言ってるんです。
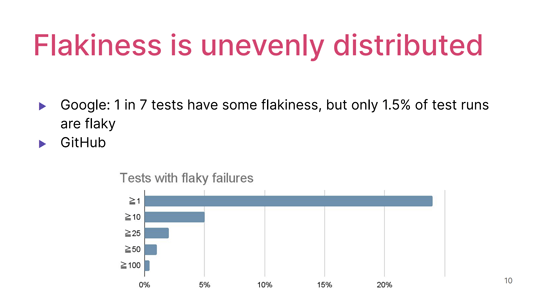
テストランがフレイキーだ、ということは実行した結果失敗が起こったということなので、Googleでも100個に1個ぐらいのテストはフレイキーネスのせいで失敗しているということですよね。
これはすごいなと思います。
ただしほとんどのテストは滅多にフレイキーネスでは失敗したりしない。でも、そういう失敗していないテストにも何らかのフレイキーネスが存在している。だから、7つのテストのうち1つには何らかのフレイキーネスの問題があると、そう言っているわけです。
GitHubは別の見方で同じことを示しています。
あるテストがフレイキーな失敗をした回数を見ると、一番上のマーカーを見ると23%が24%ぐらいのテストで最低1回はフレイキーの問題を起こしている。
一方、一番下のこの1%ぐらいのテストは、なんと100回以上フレイキーネスで失敗する。
これはある種の希望をもたらす結果で、つまりこの100回以上フレイキーネスで失敗しているテストのフレイキーネスを解決できれば、少しの労力でより大きなインパクトを得られるのではないだろうか、ということを示唆するわけです。
逆に言えば、フレイキーネスを完全にテストから取り除くのはかなり難しいということでもあります。テストの23%か24%には何らかのフレイキーネスがあるのだから、それらを全部テストスイートから取り除こうとしたら途方もない時間がかかる。だから、それはやっぱり諦めざるを得ない。そういうことも言えるかと思います。
だとすると、テストに関わっている人は、フレイキーネスに対処する事を完全に放棄してしまって、ゴキブリがはびこるキッチンのようなテストスイートにしてしまうか、逆に教条主義的にフレイキーネスは絶対駄目なんだと言って周囲と摩擦を生むか、どっちかになってるような気がするんです。
でも、その中間的なアプローチが必要なのではないか、とこれを見て感じます。
こうしたフレイキーネスについて、これまでどう調べられてきたかというと、本当にいろんなチームがいろんな調査をやっていて、幸いなことに、それについて発表しているんです。

- Spotify:Test Flakiness – Methods for identifying and dealing with flaky test
- Google:Google Testing Blog: Flaky Tests at Google and How We Mitigate Them
- Google:Taming Google-Scale Continuous Testing
- Shopify:The Unreasonable Effectiveness of Test Retries
- GitHub:Reducing flaky builds by 18x
- Dropbox:Athena: Our automated build health management system
- Facebook:Probabilistic flakiness: How do you test your tests?
3つの柱。つつがなくデプロイし、計測し、フィードバックする
これらを読み比べていて、大きな構図としてはこの3つの柱があるんだな、ということが僕には分かりました。

1つ目は「Keeping builds green」と書いたんですが、要するにソフトウェアデリバリーパイプラインをちゃんと動かしていく。フレイキーネスによって所々で小さな火の手が上がるんだけれども、そういう火の手が上がっても、全体としてつつがなく変更がプロダクションにデプロイされていくようにする。そこに注力する。
2つ目は「Mesuring flakiness」、フレイキーネスを計測する。やっぱり定量的に計測することが大事です。
3つ目は「Escalating flakiness」で、計測した結果をどうやってデベロッパーにフィードバックして見せていくか。
この3つの柱はお互いに補完する関係にあって、この3つが全部揃わないとうまく回らないんだということを感じました。
1つ目は当たり前かなと思うんです。つまり、デリバリープロセスの最終的なゴールはコードをお客さまに届けるということだから、それが止まったらどうにもならない。
ただし、デリバリープロセスを動かし続けるということは、ある意味でフレイキーネスが発生してることが分からなくなることなので、分からないままだと解決に向かわない、だからそこは困る。
だからそれを定量的に測りましょうと。
測ることの目的は、それをデベロッパーにフィードバックして問題を改善するということです。フレイキーネスを解決するうえでどこに労力を集中したらいいのかを判断するためには、計測した結果をデベロッパーにエスカレートする必要がある、ということになります。
この3つの柱についてそれぞれどういうことがされてるのかについて、次は話していこうと思います。
≫後編に続く。後編ではフレイキーネスを受け入れつつソフトウェアデリバリーパイプラインをちゃんと動かしていくこと、フレイキーネスを計測すること、そしてフレイキーネスを開発にフィードバックすることの3つの柱について解説します。
関連記事
ソフトウェアテストの自動化を推進する方法については、下記の記事もぜひご参照ください。
- 「アジャイルサムライ」の著者が語る、技術志向の企業が世界をどう見ているのか? そしてソフトウェアテスト自動化を進化させる方法について(前編)。JaSST’22 Tokyo基調講演
- 「アジャイルサムライ」の著者が語る、技術志向の企業が世界をどう見ているのか? そしてソフトウェアテスト自動化を進化させる方法について(中編)。JaSST’22 Tokyo基調講演
- 「アジャイルサムライ」の著者が語る、技術志向の企業が世界をどう見ているのか? そしてソフトウェアテスト自動化を進化させる方法について(後編)。JaSST’22 Tokyo基調講演