東証がSREによるレジリエンス向上に挑む理由。過去のシステム障害から何を学んだのか?(後編) ソフトウェア品質シンポジウム2022
今回は「東証がSREによるレジリエンス向上に挑む理由。過去のシステム障害から何を学んだのか?(後編) ソフトウェア品質シンポジウム2022」についてご紹介します。
関連ワード (一番最初、再開、認識等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
9月22日と23日の2日間、一般財団法人日本科学技術連盟主催のイベント「ソフトウェア品質シンポジウム2022」がオンラインで開催され、その特別講演として株式会社日本取引所グループ 専務執行役 横山隆介氏による「日本取引所グループシステム部門の取組み ~システムトラブルからの学びと今後の挑戦~」が行われました。
現在、日本取引所グループ傘下の東京証券取引所(以下、東証)は、過去に何度か大きなシステムトラブルを経験し、それを教訓として組織とシステムの改善を続けています。
そこで今回、シンポジウム企画委員会からの要望を受けて行われた特別講演で、東証がこれまでのシステム障害から何を学び、そこから何を変化あるいは進化させてきたのか。わずか2年前のNASのハードウェア障害への振り返りも含めて語られます。
その上で、先進的な運用の取組みとされるSREに東証がなぜ挑戦しているのか、その理由と背景についても説明されました。
本記事はその講演の内容をダイジェストとしてまとめたものです。本記事は前編と後編で構成されています。いまお読みの記事は後編です。
ベンダー丸投げをやめ、サイロ化していた運用部門を統一
そこでようやくこのスライドの話に入っていけるわけなのですけれど、その2005年、2006年の東証にとって本当に歴史上非常にインパクトのある出来事があった。そして真摯に反省をした。
そして、システム部門の整備に対して非常に大きな力を注いでいくことになります。
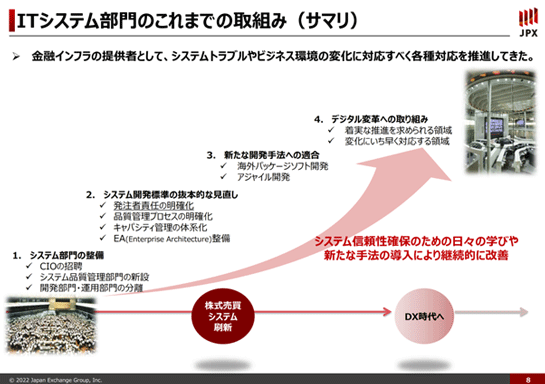
まず、CIOをというポジションを作るのですが、残念ながらCIOを担える経験、あるいはケイパビリティというのかもしれませんが、そうしたものを備えた人間が社内にはおらず、外部から招聘するということになりました。
そこでNTTデータにいらっしゃった鈴木さん(鈴木義伯氏)を初代のCIOとしてお招きし、強いリーダーシップや知見と、それからこれが非常に大事なのですが、当時のIT部門の頑張りが合わさって、その後のさまざまな施策を行っていくこととなります。
施策は様々ありますが、システムの開発全体のプロセスを抜本的に見直して、システムの品質を確保することに邁進していくことになります。
また、開発部門と運用部門を分離し、運用部門は完全に統合しました。
それまではベンダーに丸投げしつつ、ベンダーごと、例えば富士通や日立、NTTデータなどごとに縦割りになっていて開発と運用は分離されておらず、システム部門ごとに完全にサイロ化されていました。
そこを開発と運用を分離した上で、運用部門は全システムで統一した部署とし、当時の東証の標準的な運用スタイルに全部合わせました。
例えば売買システムの運用管理は富士通のSystemwalkerを使っていて、清算システムは日立のJP1を使っているところを、いろいろ抵抗があるなかで全部JP1に統一して可視化をする、といったことをしていたということです。
さらに、これはよくある話だとは思うのですが、部門が「業務」「システム開発」「システム運用」とあるとすると、業務部門が一番上で、システムの開発部門ではその下請けで、システムの運用部門はさらに開発の下請け、みたいな力(ちから)関係になりがちです。
そうなると業務部門は開発部門に対して要求を言いっぱなしで、開発部門はそれを聞いて作ったら、あとは運用部門に投げっぱなし、ということになってしまいます。
これでは、システムの安定運用をしようとしても絶対できません。だからこの力関係を逆にする、ということをずっとしてきました。
システム障害は運用しているときに発生します。ですから、システムを安定的に何年も運用するためには運用部門がとても大事になるのです。
発注者責任を明確化する
元CIOである鈴木さんが信念として強く言っていたのは「発注者責任を明確化する」ということです。
発注者とは我々です。我々が、システムを開発する上での責任というものを明確化する。突き詰めるとそれは、ウォーターフォールの開発で言うと要件を我々がいかに明確に出せるかというところに尽きると思います。
以前は要件もベンダーに書いてもらっていたわけです。基本設計はおろか要件定義書から、もうベンダーに作成してもらっていた。
でも、それはもう全然駄目です。今でも我々がすべてを完全に作っている、というわけではありませんが、基本設計書も詳細設計書もシステム定義書も、それからテスト計画書も全部、我々がレビューしています。
そしてベンダーの工程に入ったとしても、そこでブラックボックスにせずに、途中の基本設計のプロセスでも詳細設計でも必ず品質評価をします。ベンダー内の単体テスト、システムテストも含めて全部結果を見て、ディスカッションもします。キャパシティ管理も相当体系化をして実施しています。
そうやって発注責任をきちっと明確化し、丸投げはしない。システム障害の責任は一義的にはベンダーでなくて我々です。我々の責任としてきちんと品質を高める必要があります。
一連の対応を頑張ってやり遂げて、その一つの成果として、初代のarrowheadが2010年に稼働しました。
2005年から2006年にかけて非常に深刻なシステム障害があり、初代のCIOが2006年に就任してから4年ぐらいかけて品質や運用の整備をし、それと並行して新しい売買システムをスクラッチから開発をして、2010年に稼働したわけです。
運用部門の地位を向上させるための取組み
運用部門の地位を向上させると先ほど申し上げましたが、実際そうなるような仕掛けとして、一つは運用を司る「ITサービス部」に「運用標準」という規約を作らせまして、基本的にはその規約を満たしていないと開発部門から出てきたシステムを受け入れません。
運用テストの項目もたくさんありまして、テストで出てきたバグも潰して、運用テストをクリアしないと実稼働させません、という仕組みにもなっています。
また、現在ではシステム開発の際に、将来そのシステムを受け入れることになるITサービス部の担当者を開発に参画させます。
そうして一緒になって、運用設計、運用テストをやりながらシステム開発をしていく。最終的にそのシステムの運用を受け入れるときには、開発に参画していたITサービス部の担当者はITサービス部に戻る。すると開発の経緯もよく分かっているシステムを運用受け入れする形になります。
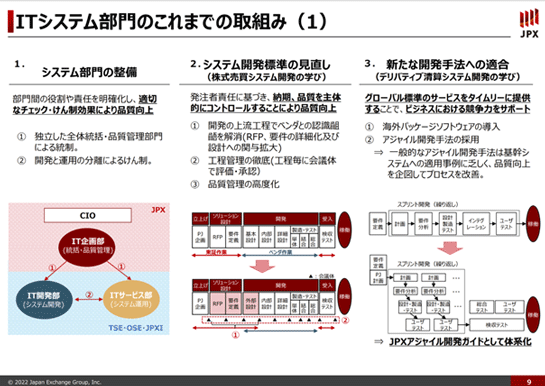
さらに、障害などが起きたときには開発部門が問題を分析するだけでなく、必ずITサービス部にも分析をさせます。そうして開発部門からの一方的な目線だけではなく運用サイドからも分析をチェックして、両方を合わせて問題点をあぶり出します。
もちろん開発部門から運用部門に対してもの申すこともあるわけで、いい意味で部門相互の健全な牽制といいますか、システム品質や開発品質を含めた全体品質を向上させるようなサイクルが回っているのではないかと思います。
そのためにはやはり、ITサービス部という運用の主体の存在が極めて大事かなと思います。
2020年10月に発生したシステム障害
次に、2020年10月1日に発生した東証のシステム障害の話です。
今から2年前のことで新聞などでも大きく取り上げられましたので、ご記憶の方も多いかと思います。
NASという共有ディスク装置のハードウェアが故障しました。そうすると本来はバックアップ用の機器にフェイルオーバーする仕組みがあるのですが、そのフェイルオーバーがうまくいかなかった。それが原因となり全銘柄の売買が停止し、終日売買が停止しました。

下記のスライドの中央部分に書いてあるのですが、故障した共有ディスクはメモリ故障時に自動切替が機能しないことが判明しました。これは設定の間違いで、大きなシステム障害でも原因は単純なことから起きるということを改めて認識しました。
また、これはオープンになっている情報なので申し上げて構わないと思いますが、調べてみるとこの設定がマニュアルと実装で違っている、といったこともありました。
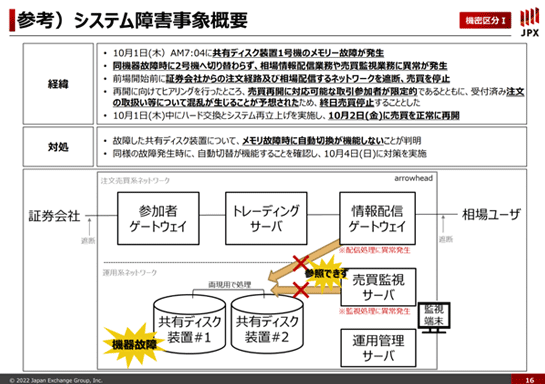
そこで、我々は今後の対策として機器購入プロセスや機器導入時のテストの仕方なども含めて全面的に見直すことにしました。
障害は起こるものだから、回復力も大事である
このシステム障害の経験からもいくつか学びがありました。これは最近バズワードになりつつあるかもしれませんが、「障害回復力」つまり「レジリエンス」です。
これまで、特にarrowheadは高可用性が重視され、基本的にはできるだけ止まらないことを大きな目標として開発運用をしてきました。
それは一定程度は達成されていたと思いますが、でも、やはりシステム障害というのは起こるものです。そのときのために障害からの「回復力」をいかにして高めておくかが大事になります。
今回の障害は終日売買停止になりましたが、取引所としてその日のうちに回復させて売買が再開できなかったのかと強く問われました。
このことから、できるだけ早期に障害から回復させることは高可用性を達成することと同じぐらい大事な要素なのだ、ということを改めて認識をしました。
レジリエンスはステークホルダーを巻き込んで作るもの
このレジリエンスを高める仕組みは開発だけではなく運用にも関わりますので、様々な復旧の手順や障害復旧のための訓練があります。
ただし一番最初にご説明した通り、我々のシステムというのは、極めて多くの外部関係者との接続において成り立っています。そうすると我々だけではレジリエンスは実現できません。
例えば相場情報を配信する通信社、注文を発注する証券会社なども機能することで、全体として日本の証券市場というものが運営されているということです。
実はこの障害のときも、当日中に売買システム単体の再立ち上げができそうな目途はありました。しかしその周りの接続先も含めた全体回復は難しそうだということで終日売買停止することになりました。
こうした事例を念頭に置いた、取引参加者も含めたシステムの再立ち上げ障害回復訓練ができていなかったと、これも非常にご指摘を受けたところです。
もちろんできなかったことには様々な理由がありました。例えば訓練をするための負担は証券会社にも大きくかかるわけで、それらを開発期間の中で100%全部やるのは実際には難しい。
でも、そうしたケースの重要性を認識した後では、何らかの方法があったのではないかと思います。
そこで、レジリエンスに対してきちんとリソースを割いて、周りのステークホルダーを巻き込んでレジリエンスを作っていくことを大きな学びとして、次の世代のarrowheadを去年から開発しています。
レジリエンス向上のためSREに取り組む
JPXとしてレジリエンスをさらに向上させるための色々な施策に取り組んでいる中の1つとして、システム運用についてもう一度見直すことに取り組んでいます。
具体的には、2005年から2006年にかけての障害からの反省として取り組んだ運用部門の統一について、これを変えてみようということです。
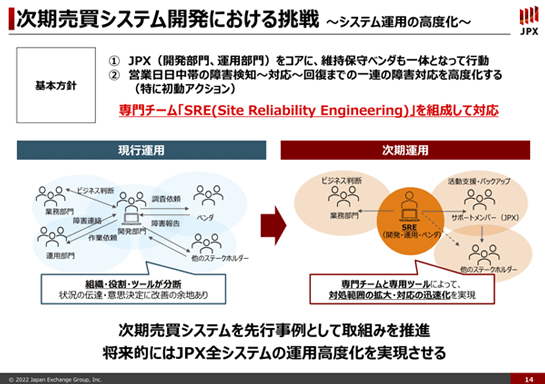
障害を迅速に検知し、再開するためのレジリエンスの向上は、今の統一された運用部門と全システム標準的な運用の仕方を壊さないと実現できないのではないか、という問題意識からです。
開発部門と運用部門、これを「SRE」(Site Reliability Engineering)という仮称のチーム名で呼んでいますけれども、ここに集約させます。加えて、ベンダーも入ります。
今までは、障害の検知と問題の切り分けは運用部門がやり、そこから先の、例えばリカバリのような作業は運用部門だけではできないので開発部門も巻き込んで、最終的にはチームで対応する、ということになります。
それを最初からSREに集約しようとしています。
さらにarrowheadのSREに特化した専用のツールを開発することで、障害への対応範囲の拡大と時間の短縮化ができないかと取り組んでいます。
これがうまく機能して、かつ健全性の形成機能も維持できそうだということになれば、最終的にJPX全体にフィードバックして、JPX全体の運用を一段と高度化できるのではないかと考えています。
次期arrowheadが動くのが2024年度後半としているので、あと1年半から2年ぐらい、検証しながらこの組織を作り上げていくことにしています。
障害とその反省をきっかけにITのレベルを引き上げていく
やはり障害が発生すると社会に対して大変なご迷惑をおかけしますので、真摯に反省しなくてはならないことが大前提です。
一方で障害が起きるということは、時代の変化に対する我々のIT部門の持つ歪の表れみたいな面もあるように感じています。
それを教訓として前向きに捉えて、我々のITのレベルを一段引き上げるにはどうすればいいかを考える。それは運用のやり方を変化させたり、ステークホルダーも含めたレジリエンスを作り上げることであったりする、そういった改善のきっかけにできればと考えています。
そろそろ終了時間がとなりましたので、私の話は以上とさせていただきます。ありがとうございました。
関連記事
Publickeyでは10年前にarrowheadが開発されたときも、東証の講演を記事にしていました。
- 客が本気にならないといいシステムができない。東証arrowhead成功の鍵とは ~ Innovation Sprint 2011
- 「絶対落ちないシステムを作れ」という要件に、開発者たちはどう対応したのか。東証arrowheadの当事者が語る