オラクル、インメモリDBのMySQL HeatWaveに機械学習機能を追加。SQL文だけで学習、推論、説明の取得を実現
今回は「オラクル、インメモリDBのMySQL HeatWaveに機械学習機能を追加。SQL文だけで学習、推論、説明の取得を実現」についてご紹介します。
関連ワード (処理、利便性、実現等) についても参考にしながら、ぜひ本記事について議論していってくださいね。
本記事は、Publickey様で掲載されている内容を参考にしておりますので、より詳しく内容を知りたい方は、ページ下の元記事リンクより参照ください。
オラクルは、MySQLにインメモリデータベースエンジンを搭載することで高速なOLAP機能を提供する「MySQL HeatWave」の新機能として、機械学習機能を提供する「MySQL HeatWave ML」を発表しました。
同時に、無停止でのHeatWaveのノード拡張と、ノードあたりのデータ格納量の倍増も発表されました。
[プレスリリース抄訳] オラクル、MySQL HeatWave MLを発表 – 開発者が簡単、迅速、経済的に利用可能なMySQL アプリケーション向けの強力な機械学習機能を提供 – Oracle Cloud Infrastructure(OCI)の東京と大阪を含む37のリージョンでご利用可能です https://t.co/ly7qGP8CZ5 #mysql_jp #機械学習 pic.twitter.com/AwQ0zVGFeT
— MySQL_Jp (@mysql_jp) March 30, 2022
オラクルはOracle Cloudで提供しているMySQLデータベースのマネージドサービス上に、スケールアウト可能なインメモリデータベースエンジンによって高速なOLAPを実現した「MySQL HeatWave」を追加しています。今回発表されたのは、このMySQL HeatWaveにおいてOLAPだけでなく機械学習による推論などを可能にした「MySQL HeatWave ML」です。
これでオラクルはOracle Cloud上のMySQLデータベースサービスにおいて、InnoDBによるOLTP、HeatWaveによるOLAP、HeatWave MLによる機械学習を統合したことになります。
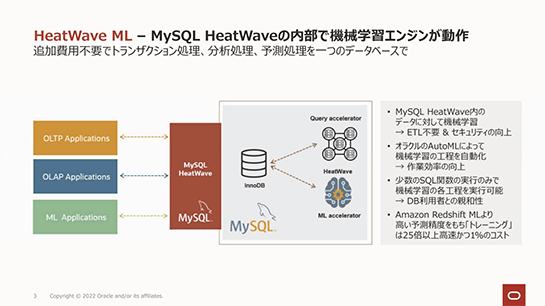
ユーザーはこの3つの処理の切り替えをほとんど意識することなく、1つのデータベースに対してSQL文を投げるだけで望む処理が可能になります。
一般的にはOLTPとOLAPと機械学習はそれぞれ別々のサービスに分かれており、OLTPで蓄積したデータを別のデータウェアハウスなどに転送してOLAPによる分析などを行い、さらにそのデータを機械学習サービスに読み込ませることで学習と推論を行うことになります。
この場合、対象となるデータの数倍のストレージ容量が必要となり、大規模なデータ転送には時間がかかるためタイムリーな分析などが難しく、またデータが転送されるたびにセキュリティを保つのが難しくなるなどの課題がありました。
これに対して、MySQL、HeatWave、HeatWave MLは1つのサービス上で統合されています。またHeatWaveはインメモリデータベースとはいえ数十テラバイトものデータを分析可能で、これがデータ転送することなくそのまま機械学習のデータセットとして利用可能な点は、従来の課題を解決する即時性や利便性を実現できる大きな特徴とされています。
アルゴリズムは自動選択、SQLだけで学習、推論が可能
HeatWave MLでは、Oracle Autonomous Data Warehouseの機械学習機能にも搭載されている「AutoML」を搭載しているため、機械学習処理においては適切なアルゴリズムなどが自動的に選択されます。
ユーザーは機械学習に関する専門的な知識やプログラミング能力を持たなくとも、SQL文により学習対象を指定し、同じくSQL文で推論結果を取得するなど、簡単に使い始めることができます。
また推論結果に対してどの特徴量が重視されたのかもSQL文で取得できることがHeatWave MLの大きな特徴とされています。これにより、なぜその推論結果が得られたのか、その理由を知ることが可能です。
今回、HeatWaveそのものも強化されました。1つは無停止でのノード拡張、そしてもう1つはノードあたりのデータ格納量の倍増です。
HeatWaveはスケールアウト可能なアーキテクチャを備えていますが、ノード数を増やすには一度クラスタを停止する必要がありました。今回の新機能で、クラスタを停止することなくノードを追加することが可能になりました。
また、HeatWaveのノードあたりのデータ格納量が倍増となりました。
HeatWaveはインメモリデータベースであり、各ノードごとにデータがメモリに格納され、処理されます。従来このノードごとに格納できるデータは410GB程度でしたが、効率的なジョインを実現するブルーム・フィルタの導入と、圧縮率の高いアルゴリズムの採用によって、1ノードあたりに格納できるデータが2倍の820GBとなりました。
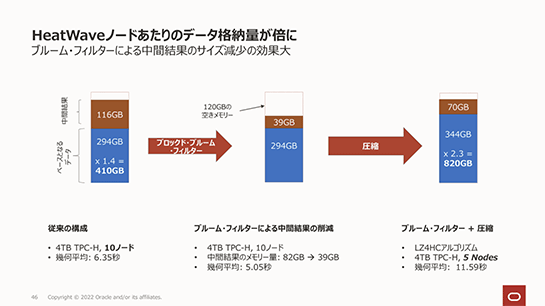
これにより従来のノード数の半分で同じ量のデータを格納できることになります。